The British National Corpus (BNC) is a carefully-selected collection of 4124 contemporary written and spoken English texts, primarily from the United Kingdom. The corpus totals over 100 million words and covers a representative range of domains, genres and registers. The entire corpus has been analyzed and marked up with part of speech (PoS) tags. Provenance and other attributes are carefully documented for each text. "What is the BNC?" provides a succinct overview of the corpus; for an exhaustive description, consult the British National Corpus Users Reference Guide. Chapter 1 of Guy Aston and Lou Burnard's BNC Handbook includes an informative survey of possible uses of corpora in general and of the BNC in particular. Additional useful information and resources (including various frequency lists with more refined PoS tagging) are found on the companion website for Word Frequencies in Written and Spoken English based on the British National Corpus by Geoffrey Leech, Paul Rayson and Andrew Wilson. The introduction includes a very readable discussion of how the corpus was tokenized and tagged.
PIE incorporates a database derived from the second or World Edition of the BNC (2000), but is not affiliated with the BNC Consortium. It aims to provide a simple yet powerful interface for studying words and phrases up to eight words long appropriate for both experienced researchers and novice users. For investigating words in longer contexts, the full BNC corpus and Xaira search and analysis software is available on CD-ROM from the BNC Consortium (a single user license costs only £ 75). Alternatively, one can look up individual words and phrases online.
To understand and interpret the datasets produced here and to compare them to results of direct queries to BNC, please read how and why the original data were normalized to build the PIE database.
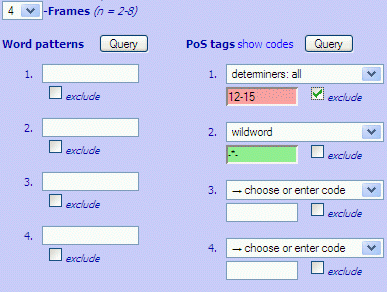
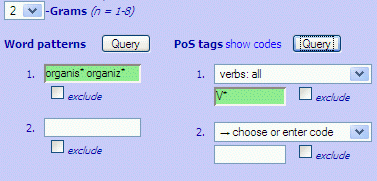
Explore the distribution of words and phrases in English via various query interfaces:
Each query returns datasets in "chunks" of up to 100,000 items, and queries can be repeated until all matching data have been retrieved. Results can be ordered alphabetically, by frequency or by PoS tag. For focused studies, users can "filter" results for specific word-forms and / or word-classes which a query must match or exclude. All query interfaces offer full support for wildcards. A click on any phrase brings up example concordances from the BNC. Details are found in the tutorials.
Sample uses of filters include searches for... click description to show actual query
This site also supports querying with regular expressions and downloading an entire dataset matching a query in tabbed format for import into a database. Ultimately tools developed for KWiCFinder and kfNgram will permit browsing and analysis of the datasets via a graphical user interface on the PC. Slight modifications to data normalization conventions may result in minor discrepancies in frequencies reported for the two versions of the database. Major changes to this site will be announced on the Corpora, Linguist and Corpus Linguistics and Language Teaching lists.
First and foremost* this site owes its very existence to the monumental achievement of the BNC development team. After months of reading and re-reading every bit of documentation and rooting around in the SGML-encoded data I have profound respect and gratitude for their efforts and accomplishments. We all look forward to future updates to the corpus. [*234 occurrences in the BNC ]
As site developer I also gratefully acknowledge my debt to Michael Stubbs of the University of Trier for fruitful e-mail discussions that led to the creation and refinement of this database and Web site. It was Stubbs who generously suggested that I add support for "phrase-frames" to kfNgram. This concept originated with his research assistant Isabel Barth, who also implemented the original phrase-frame generator. Their collaboration led to the insightful paper "Using recurrent phrases as text-type discriminators: a quantitative method and some findings" (Functions of Language (10, 1, 2003). kfNgram was originally developed for a comparative study of a corpus I compiled from the Web with data from the BNC. When I remarked that generating lists of all the n-grams and phrase-frames in the BNC would really test the limits of kfNgram, Stubbs encouraged me to do it and suggested breaking the lists down further by domain and genre. The goal has evolved from a collection of overwhelmingly large static lists into databases which produce manageable datasets tailored to the user's research needs. Four of Stubbs' works available online survey and illustrate core concepts and point the way to exploring words and phrases:
Finally I am indebted to David Lee for permission to incorporate portions of his spreadsheet BNC Index for the BNC World Edition in the database. Users are encouraged to consult his thorough discussion of the issues of classification by "text type" in: Lee, David Y. W. 2001. Genres, registers, text types, domains and styles: clarifying the concepts and navigating a path through the BNC jungle. Language Learning & Technology, Vol.5(3): 37-72.
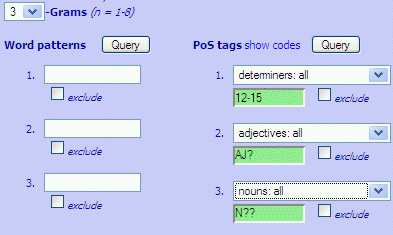
 Simple search requires + as a "wildword" symbol to match any word-form.
Simple search requires + as a "wildword" symbol to match any word-form.