
Please take a moment to read the FAQ to understand what this site means by n-grams and phrase-frames, and how the BNC defines words and tags them grammatically with POS codes. Then familiarize yourself with the normalization conventions which are specific to this database. Finally, please remember that this site contains only a subset of the words and phrases in the BNC, those occurring three times or more.
|
The drop-down menu under "Grams" affords access to all the query interfaces. The |
The following discussion shows screen shots from the "Explore N-Grams" page. Important differences for "Explore Phrase-Frames" are outlined at the end.
Clicking on one of the "Explore..." links launches a frameset with a query pane on the left and blank pane for query results on the right. If either side is too narrow, a scrollbar appears at the bottom of the window. The relative sizes can be changed by clicking on the divider, holding down the mouse button, and dragging the divider to resize the panes.
While numerous [Query] buttons are strewn around the page for convenience, they are actually unnecessary: just hit the "Enter" key to submit a query.
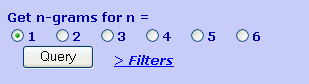
Select the number of words in
n-grams or phrase-frames by clicking on the radio button to the left of the
number. Try each number to develop a feeling for the kinds of datasets
which match each value of n. A value of 1 returns a list of
individual words. The highest-frequency two-word phrases tend to be fragmentary
building blocks of language, including "de-fused" contractions like do n't, I
'm; other useful groups of 2-grams are compound nouns written as two words
as well as adjective-noun and adverb-adjective collocations. Recurring
3-grams and 4-grams are often (almost) complete familiar phrases. The larger
n is, the larger the number of distinct n-grams in the corpus grows, while
the percentage of n-grams meeting the cutoff criteria (here: minimum of 2
occurrences in the corpus) declines. For n values of 5 and greater,
formulaic expressions restricted to highly specific circumstances become
increasingly prominent in the data, and the total frequency of any given 5- or
6-gram is relatively small. For example, there are almost 1.6 M 3-grams occurring 5 or more
times, and over 1.3 M 2-grams; in contrast, less than half the former number of
4-grams cross the threshold, and the number of 6-grams that qualify is less than
4% of the figure for 3-grams. Values of n greater than
6 almost exclusively reflect formulaic language and quotations.
Note the links to jump down to the word-form and POS-code filters, as well as the ubiquitous [Query] button.
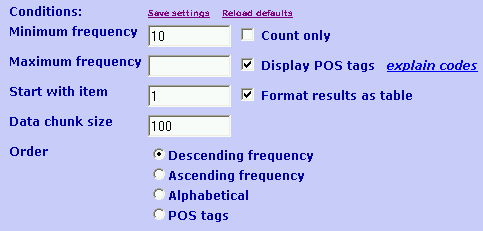
The options in this section display "tool tips", i.e. short explanations that
pop up when you hover your mouse cursor over them. Several display options appear in the right-hand column. As a general rule,
for efficient querying you should limit the display options to what you actually
need.
Order specifies (you guessed it) the order in which items are displayed: from most to least frequent or vice-versa, in alphabetical order of the items, or in alphabetical order of the POS tags. If you choose an order other than alphabetical, items with identical values for the primary sort key appear in alphabetical order of the word or phrase. Alphabetical sorts are the most efficient option.
![]()
Without filters, every item that meets your numeric conditions is
included in the results dataset, which degrades database response time. Filters narrow the dataset down to items
which match specific criteria. You can match word-forms, POS tags, or both; if
both criteria are specified for a given position, items must match all
criteria (logical AND) to pass the filter.
To match alternate word-forms or POS tags, enter them all in the same field separated by spaces (logical OR).
Unfortunately there are no semantic filters. For example, by specifying both word-form and POS tag you can distinguish the verb match from the noun, but you cannot distinguish instances in which the latter means 'sports contest' from 'incendiary device', 'corresponding entity' etc.
Both word-form and POS filters support wildcards: * matches any number of characters; ? matches one character, no more, no less.
Check the exclude box to eliminate the forms or tags you specify from the dataset: then only items which do not match your specifications are retrieved.
If there is an entry in a filter field, the field is colored light green, or else light red if the exclude box is unchecked: . These color codes make it easy to spot which fields have entries and whether they specify inclusion or exclusion.
Note the < Top link to jump back to the top, e.g. to change the value of n. Decreasing the value of n hides some of the filter fields, but the values are preserved and reappear when the higher value of n is restored. Careful: clicking the Clear Filters button erases everything directly, without confirmation. It is a good idea to click this button when starting a new query lest you unintentionally carry over filters from a previous search.
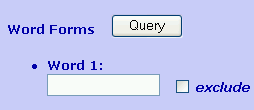
The Words & Phrases Database
normalization process converts all characters to lower case, so matching is
not case sensitive: Pole and pole both return the same dataset.
To match more than one specific word-form, it is generally most efficient to specify all forms, separating them with spaces: country countries will match only
these two forms, while wildcard countr* matches additional forms such as countrified, countryman, and
countryside, resulting in a larger dataset with unnecessary items. You can increase
the number of useful matches by specifying orthographic variants such as
realise realize and database data-base.
The corpus preserves the spelling of original texts, so compound forms might be written together as a single word, with a hyphen, or as two separate words. Consequently you may need to run separate queries searching on up to three possibilities: Query 1, Word 1 database data-base || Query 2 Word 1 data Query 2 Word 2 base or Query 1 Word 1 much-needed || Query 2 Word 1 much Query 2 Word 2 needed.
In the normalization process sentence punctuation was removed. Three kinds of punctuation remain within word-forms:
hyphen - in hyphenated forms: much-needed
underscore _ in "multiword units": of_course in_spite_of
apostrophe ' in contracted forms and possessives, typically "de-fused" into separate word-forms: she 's does n't
Using wildcards you can find forms with these punctuation marks: *_* matches all multiword forms with underscore, and *-* returns hyphenated forms. Forms with apostrophes are "de-fused" into their components; to reconstruct them look for 2-grams and specify *'* for word 2.


The
CLAWS
parser assigns each "word" in
the corpus a Part Of Speech (POS) code as
detailed here. These codes may
be specified in various ways:
Enter the three-letter POS code directly in the field, separating multiple codes with spaces, e.g. NN1 NN2 matches both singular and plural common nouns. Wildcards can be used without sacrificing efficiency, e.g. N* matches any noun.
Enter the numeric values from this table. With this method, 17 18 matches both singular and plural common nouns. Numeric values can also be specified as ranges by joining the lowest and highest value in the range with a hyphen: the range 16-19 matches any noun. These numeric values are specific to this website. In some cases the POS tags have been reordered to create ranges corresponding to POS supercategories. For example, the class articles has been moved out of alphabetical order so the range 12-15 includes all determiners.
Select a POS description from the drop-down list to the left of the entry field. This list includes single POS tags and supercategories defined with both wildcards and numeric ranges. Caution: selecting a category from this list erases anything already appearing in the corresponding field.
Tip: to get a feeling for different ways to specify POS tags, select various entries from the drop-down list and study the codes that appear in the POS field.
There are several subtle differences between the "Explore N-Grams" and the "Explore Phrase-Frames" interfaces:
All kinds of query results appear in a "pane" next to the query form and have several clickable buttons at the top:
N-Grams
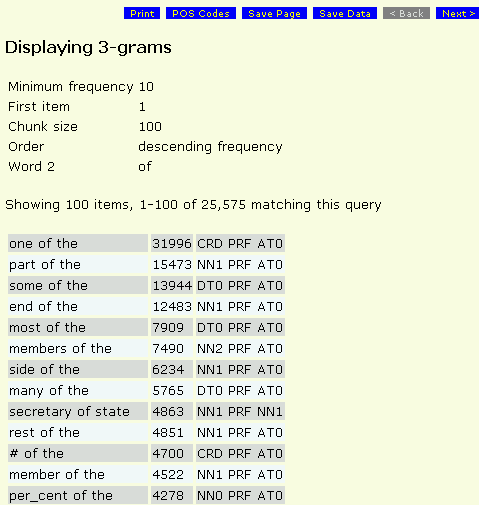
Click on any word or phrase to display a random set of 50 concordances of the
item from the corpus in a separate window.
Phrase-Frames
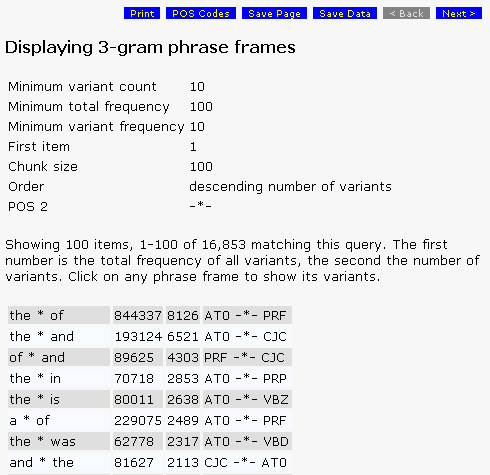
Click on any phrase frame to display variants in a separate window. The frequency cutoffs, first item and chunk size are determined by the parameters specified in the phrase-frame uqery.
Phrase-Frame Variants
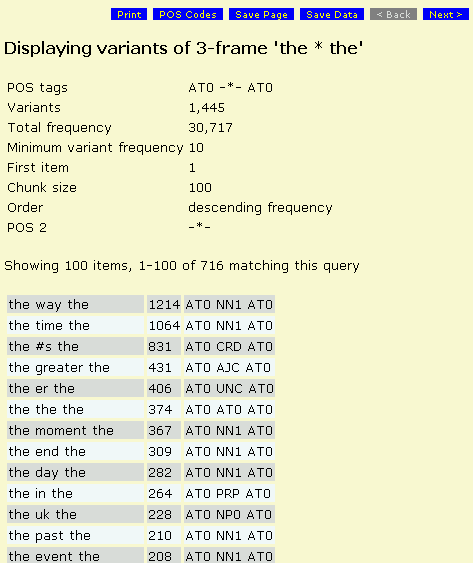
Click on any word or phrase to display a random set of 50 concordances of the item from the corpus in a separate window.